Publications

One Editor, Many Edits: A Unified Training-free Framework for Diverse Video Edits
Adheesh Juvekar, Onkar Kishor Susladkar, Kiet A. Nguyen, Nabeel Bashir, Xiaona Zhou, Muntasir Wahed, Vedant Shah, Ismini Lourentzou
In preparation • 2026
A training-free editing framework that reuses a single editor to support diverse video edits across multiple tasks without per-task training.
In preparation

GraphVid: Interactive Graph Control Video Generation
Vedant Shah, Onkar Kishor Susladkar, Tushar Prakash, Kiet A. Nguyen, Tianjiao Yu, Adheesh Juvekar, Muntasir Wahed, Ismini Lourentzou
In preparation • 2026
GraphVid lets users steer video generation via interactive graph controls that align structure, motion, and semantics.
In preparation

Best of Both Worlds: Multimodal Reasoning and Generation via Unified Discrete Flow Matching
Onkar Susladkar, Tushar Prakash, Gayatri Deshmukh, Kiet A Nguyen, Jiaxun Zhang, Adheesh Juvekar, Tianshu Bao, Lin Chai, Sparsh Mittal, Inderjit S Dhillon, Ismini Lourentzou
arXiv preprint arXiv:2602.12221 • 2026
We propose UniDFlow, a unified discrete flow-matching framework for multimodal understanding, generation, and editing. It decouples understanding and generation via task-specific low-rank adapters, av...
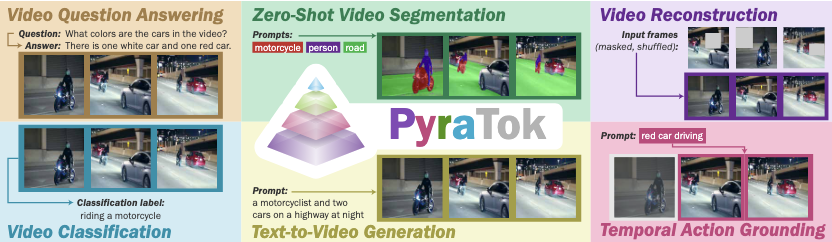
PyraTok: Language-Aligned Pyramidal Tokenizer for Video Understanding and Generation
Onkar Susladkar, Tushar Prakash, Adheesh Juvekar, Kiet A Nguyen, Dong-Hwan Jang, Inderjit S Dhillon, Ismini Lourentzou
arXiv preprint arXiv:2601.16210 • Accepted at CVPR 2026
Discrete video VAEs underpin modern text-to-video generation and video understanding systems, yet existing tokenizers typically learn visual codebooks at a single scale with limited vocabularies and s...
In preparation for camera-ready
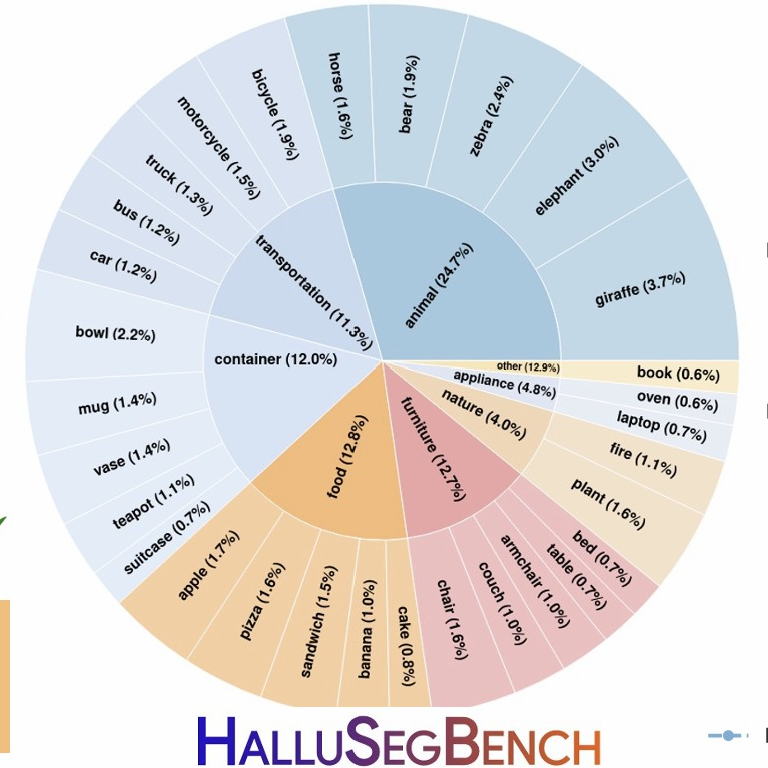
Counterfactual Segmentation Reasoning: Diagnosing and Mitigating Pixel-Grounding Hallucination
Xinzhuo Li*, Adheesh Juvekar*, Xingyou Liu, Muntasir Wahed, Kiet A Nguyen, Ismini Lourentzou
arXiv preprint arXiv:2506.21546 • Accepted at CVPR 2026
Segmentation Vision-Language Models (VLMs) have significantly advanced grounded visual understanding, yet they remain prone to pixel-grounding hallucinations, producing masks for incorrect objects or ...
* Equal contribution • In preparation for camera-ready

RewardFlow: Generate Images by Optimizing What You Reward
Onkar Kishor Susladkar, Dong-Hwan Jang, Tushar Prakash, Adheesh Juvekar, Vedant Shah, Ayush Barik, Muntasir Wahed, Ritish Shrirao, Ismini Lourentzou
Accepted at CVPR 2026
RewardFlow optimizes image generation pipelines by directly aligning outputs with user-defined reward signals, enabling more reliable control over synthesis objectives.
In preparation for camera-ready

CALICO: Part-Focused Semantic Co-Segmentation with Large Vision-Language Models
Kiet A Nguyen, Adheesh Juvekar, Tianjiao Yu, Muntasir Wahed, Ismini Lourentzou
Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) • 2025
Recent advances in Large Vision-Language Models (LVLMs) have enabled general-purpose vision tasks through visual instruction tuning. While existing LVLMs can generate segmentation masks from text prom...
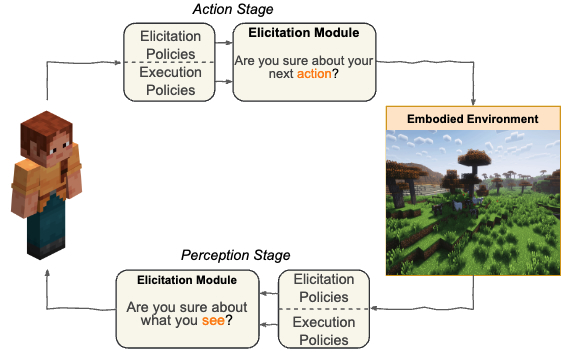
Uncertainty in Action: Confidence Elicitation in Embodied Agents
Tianjiao Yu, Vedant Shah, Muntasir Wahed, Kiet A. Nguyen, Adheesh Juvekar, Tal August, Ismini Lourentzou
arXiv preprint arXiv:2503.10628 • 2025
Expressing confidence is challenging for embodied agents navigating dynamic multimodal environments, where uncertainty arises from both perception and decision-making processes. We present the first w...
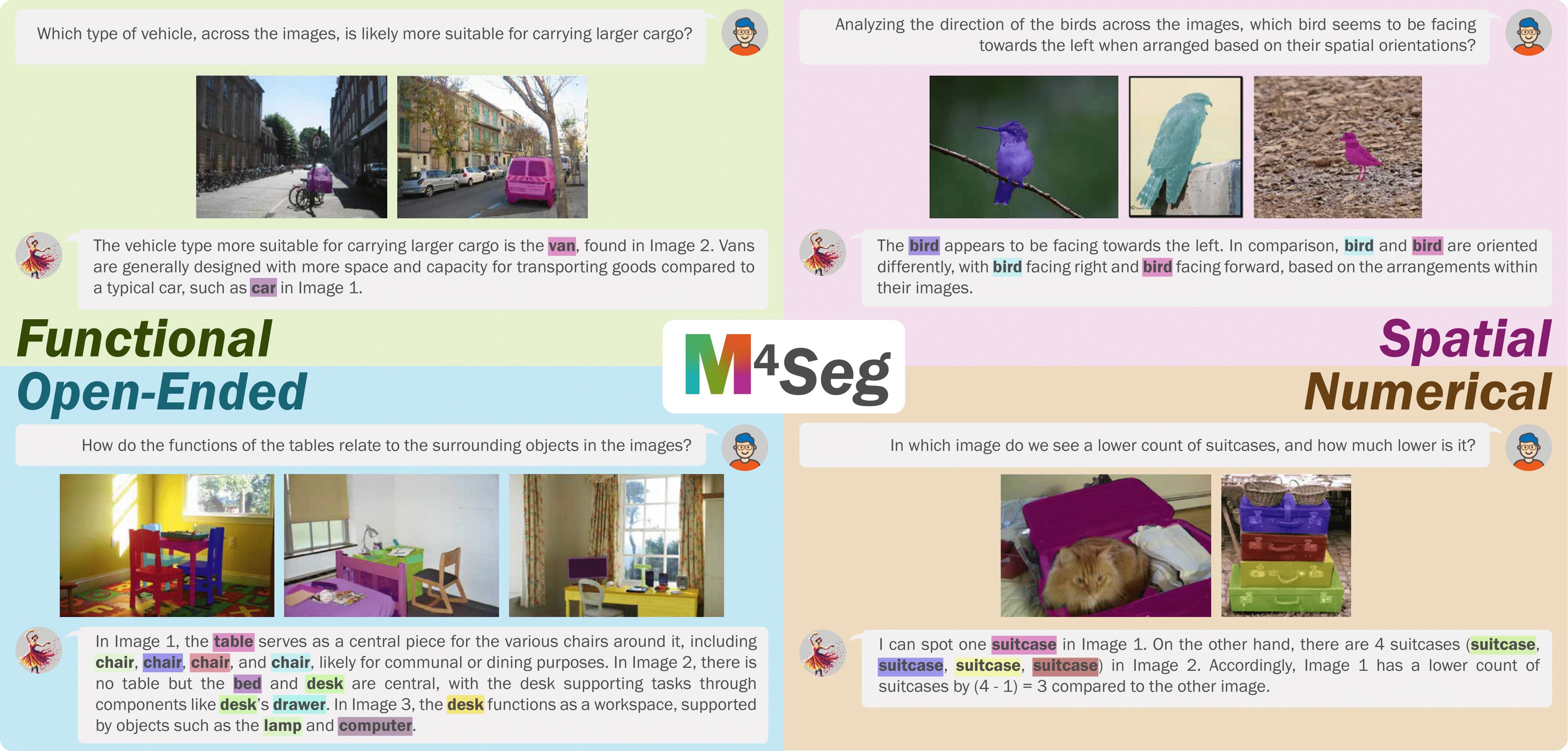
Prima: Multi-image vision-language models for reasoning segmentation
Muntasir Wahed*, Kiet A Nguyen*, Adheesh Juvekar, Xinzhuo Li, Xiaona Zhou, Vedant Shah, Tianjiao Yu, Pinar Yanardag, Ismini Lourentzou
arXiv preprint arXiv:2412.15209 • 2024
Despite significant advancements in Large Vision-Language Models (LVLMs) capabilities, existing pixel-grounding models operate in single-image settings, limiting their ability to perform detailed, fin...
* Equal contribution
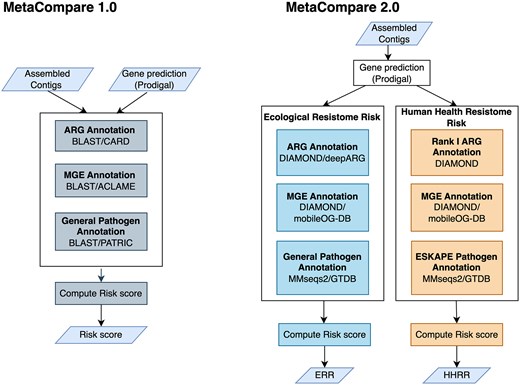
MetaCompare 2.0: Differential ranking of ecological and human health resistome risks
Monjura Afrin Rumi, Min Oh, Benjamin C Davis, Connor L Brown, Adheesh Juvekar, Peter J Vikesland, Amy Pruden, Liqing Zhang
FEMS Microbiology Ecology • 2024
While numerous environmental factors contribute to the spread of antibiotic resistance genes (ARGs), quantifying their relative contributions remains a fundamental challenge. Similarly, it is importan...